阿里发布QwenLong-L1-32B:首个强化学习训练的长文本推理模型
IT之家 5 月 27 日消息,阿里通义千问 Qwen 团队昨日(5 月 26 日)发布 QwenLong-L1-32B 模型,是其首个通过强化学习训练的长文本情境推理模型(LRM)。
在七个长文本 DocQA 基准测试中,表现超越 o3-mini 和 Qwen3-235B-A22B 等旗舰模型,与 Claude-3.7-Sonnet-Thinking 相当。

QwenLong-L1-32B 模型最大的亮点,在于上下文窗口最高支持 131072 个 tokens。该模型基于 QwenLong-L1 框架开发,采用了先进的 GRPO(Group Relative Policy Optimization)和 DAPO(Direct Alignment Policy Optimizatio)算法,结合基于规则和基于模型的混合奖励函数,显著提升了模型在长上下文推理中的准确性和效率。
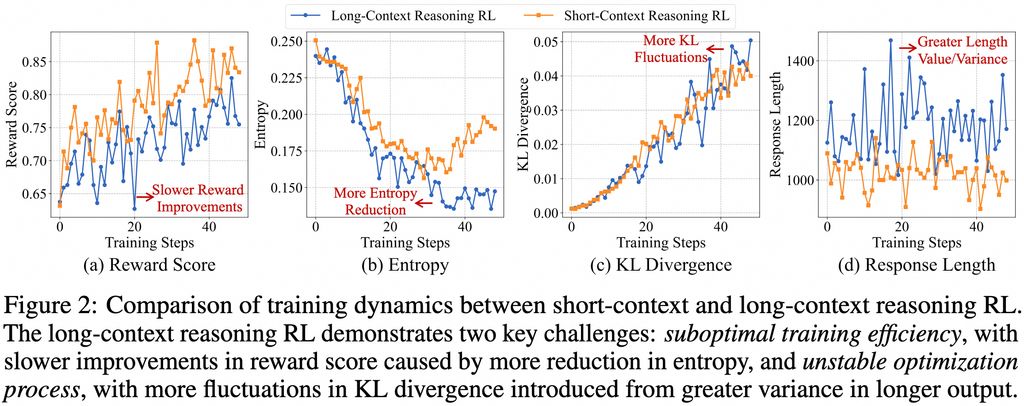
具体而言,团队在监督微调(SFT)阶段建立一个稳健的初始策略,随后采用课程引导的分阶段强化学习技术来稳定策略演变,并结合难度感知的回顾采样策略来激励策略探索。
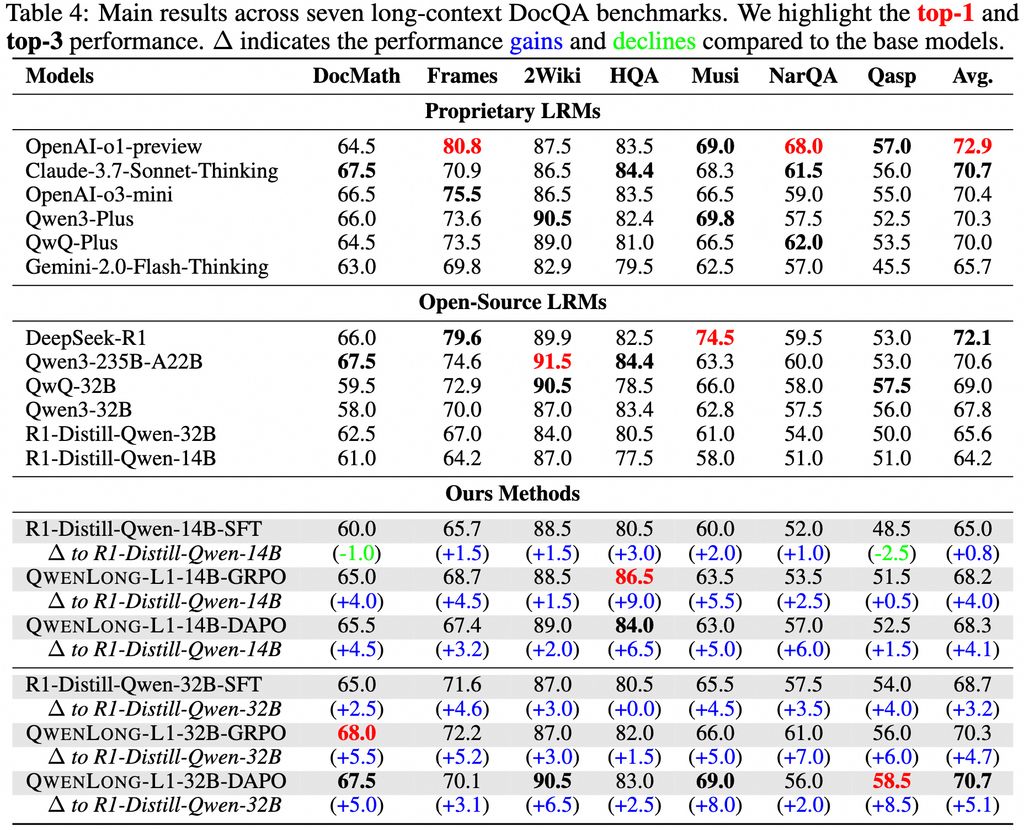
除了模型本身,阿里还发布了一套针对长文本推理问题的完整解决方案。该方案包含四个核心组件: 高性能的 QwenLong-L1-32B 模型、专门优化的训练数据集、创新的强化学习训练方法,以及全面的性能评估体系。
IT之家附上参考地址
本网通过AI自动登载内容,本文转载自MSN,【提供者:IT之家 | 作者:佚名】,仅代表原作者个人观点。本站旨在传播优质文章,无商业用途。如不想在本站展示可联系删除。